
了解了一下Spring中解决循环依赖的手段,记录一下。
循环依赖
首先需要解释一下什么是循环依赖,例如有两个对象A和B,A依赖B,B依赖A,这就构成了循环依赖,循环依赖其实是个错误的设计,在实际工程中肯定是需要避免的,例如在go中如果产生了循环依赖,直接就会编译报错,但是在spring中,针对循环依赖提出了解决方案,虽然循环依赖是错误设计,但这种解决方案却很精妙。
解决方案
我们首先预设两个对象A和B,其中A依赖B,B依赖A。在spring中,一个比较核心的方法就是refresh()方法,该方法会完成容器的创建工作并且做好一切准备工作,所以创建bean也是在该方法中完成的。而在该方法的finishBeanFactoryInitialization(beanFactory)中,最后的beanFactory.preInstantiateSingletons()方法会实例化所有未实例化的且没有设置为懒加载的bean。该方法会遍历beanDefinitionNames,最先遍历到的就是"a",会调用getBean(beanName)方法,继而调用doGetBean()方法。
1 | // doGetBean,代码省去了一些细节 |
主要关注第15行,调用了getSingleton(String beanName, ObjectFactory<?> singletonFactory)方法,该方法内会调用第二个参数,而也就是第17行的createBean()方法,在该方法中会再去调用doCreateBean()方法。
1 | // doCreateBean,代码省去了一些细节 |
在第六行,对A对象进行了实例化,注意此时只是实例化了对象,还没有进行属性填充,然后在第12行通过调用addSingletonFactory()方法将对象放到一个map中,也就是singletonFactories,即俗称的三级缓存中,注意放入的也是一个lambda表达式,接着在第16行,要完成属性填充,调用链是populateBean(beanName, mbd, instanceWrapper) --> applyPropertyValues(beanName, mbd, bw, pvs),此时发现在我们预设的环境下,A对象依赖B对象,那么,会调用valueResolver.resolveValueIfNecessary(pv, originalValue)方法,如果传入的originalValue是RuntimeBeanReference类型,则会调用resolveReference(argName, ref)方法,而这个方法里,就会走到getBean()的那一套流程,从而创建出B对象。
在实例化B对象后,同样也会进入到属性填充流程,也会进入populateBean(beanName, mbd, instanceWrapper) --> applyPropertyValues(beanName, mbd, bw, pvs)调用链,在调用valueResolver.resolveValueIfNecessary(pv, originalValue)方法时,又会进入到getBean()的流程,但此时不同的是,getSingleton()方法可以返回对象了,因为在前面创建A对象时,已经将早期的A对象加入到singletonFactories中,也就是三级缓存中,而此时,会走到三级缓存处singletonObject = singletonFactory.getObject(),调用了lambda表达式,也就是getEarlyBeanReference(beanName, mbd, bean)方法:
1 | protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) { |
这个方法非常关键,会判断是否需要进行aop,如果需要,则会在此时进行aop,然后返回增强后的对象。
1 | singletonObject = singletonFactory.getObject(); |
拿到对象后,可以看到会将对象放入到earlySingletonObjects中,也就是俗称的二级缓存中,然后将三级缓存中对应的值删除。
此时B对象的属性填充环节完毕,再进行初始化工作,最后调用addSingleton()方法将对象放入singletonObjects中,也就是俗称的一级缓存,存放完整的单例对象,然后将对象从三级缓存以及二级缓存中移除。
1 | protected void addSingleton(String beanName, Object singletonObject) { |
此时B对象创建流程结束,A对象拿到完整的B对象,进行赋值,放入单例池。自此,循环依赖得到解决。
一些思考
可以看到,spring通过三级缓存,解决了循环依赖问题,那么,为什么需要三级缓存呢,网上很多回答解释说是有可能对象需要进行aop,所以需要三级缓存来解决,但其实只需要一级缓存也能解决循环依赖问题,并且可以实现aop。
我们设计这样一个场景,A对象依赖B对象,B对象依赖A对象和C对象,C对象依赖A对象,并且A对象还需要进行aop,即存入单例池的应该是A的代理对象。
- 首先创建A对象,发现需要增强,则增强后放入单例池
- 然后进行属性填充,发现依赖B对象,而单例池中没有找到B对象,则开始创建B对象
- 实例化B对象后将B对象放入单例池,然后进行属性填充,发现依赖A对象,在单例池中找到A对象(代理对象),进行赋值,又发现依赖C对象,而单例池中没有找到C对象,则开始创建C对象
- 实例化C对象后将C对象放入单例池,然后进行属性填充,发现依赖A对象,在单例池中找到A对象(代理对象),进行赋值,结束
- 返回C对象给B对象,B对象进行属性填充,结束
- 返回B对象给A对象,A对象进行属性填充,结束
可以发现上述流程只用到了一级缓存,并且预设场景中存在多级循环依赖以及需要aop的对象,下面写了一个demo实现了上述流程:
1 | public class MyBeanFactory { |
从结果中可以看到,单例池中的对象都是完整对象,并且需要aop的对象也成功对应到了代理对象:
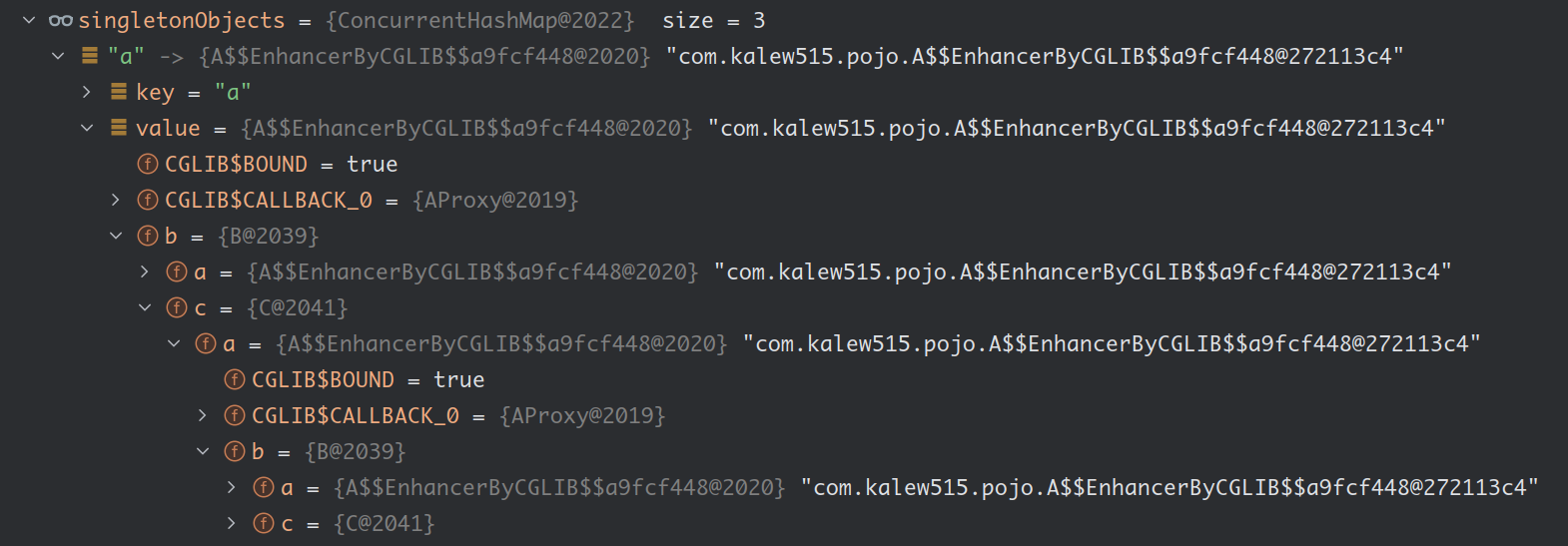
由此可见,一级缓存就足以解决这个问题,那么为什么需要三级缓存呢。
其实三级缓存解决并不是唯一解,解决问题的方法有很多,而spring选择了这一种,考虑一下上面流程中提到的一级缓存解决的方案,必须在实例化对象完毕后就立即检查是否需要进行aop,这个才是问题的关键,因为这样做破坏了原本的bean生命周期,在正常流程中,aop是在initializeBean()方法中通过postProcessAfterInitialization后置处理器去触发,而在发生循环依赖时,则是相当于在populateBean()方法进行了aop,相比正常流程稍微提前了一点。循环依赖本就是需要避免的内容,肯定是不希望因为为了解决循环依赖而去改动原始的流程,所以引入三级缓存的方式来进行解决。
另外,观察可以发现,二级缓存和三级缓存是配套使用的,三级缓存中的lambda被执行后立即将对象放入二级缓存,并从三级缓存中删除,这是为了避免多级依赖的情况下,反复执行三级缓存中的lambda表达式从而生成不一样的对象,这肯定是不可以接受的,所以需要二级缓存作为中继,二级缓存中存储的一定是经过增强的(如果需要增强)对象。
看了很久源码,spring的源码太难啃了…很多设计也非常巧妙,比如这个循环依赖问题的解决,另外其实我觉得对三级缓存这个名词不太恰当,所谓的二级缓存和三级缓存其实只是在bean的创建过程中短暂用到,后续就不会再用到,只是一个临时存放对象的map而已。
- 本文标题:spring解决循环依赖探究
- 本文作者:Kale
- 创建时间:2022-09-13 23:20:08
- 本文链接:https://kalew515.com/2022/09/13/spring解决循环依赖探究/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!